Metrics
系統指標監控
追蹤 AI 系統運行指標,掌握性能變化、錯誤與異常趨勢。
- 推論延遲與資源使用監測
- 錯誤率與行為變化追蹤
- 自定義業務與模型指標
整合指標、日誌與流程追蹤,協助團隊理解 AI 系統行為,建立排查與改善依據。
追蹤 AI 系統運行指標,掌握性能變化、錯誤與異常趨勢。
按資料政策記錄必要互動資料,支援問題排查、回溯分析與審計需求。
追蹤多步驟 AI 任務流程,協助分析延遲、錯誤與依賴關係。
整合指標、日誌與追蹤數據,支援查詢與歷史分析。
透過儀表板呈現系統狀態,協助團隊分析問題、趨勢與改善方向。
可按企業要求選擇部署與資料保留方式,控制觀測數據的存取與使用範圍。
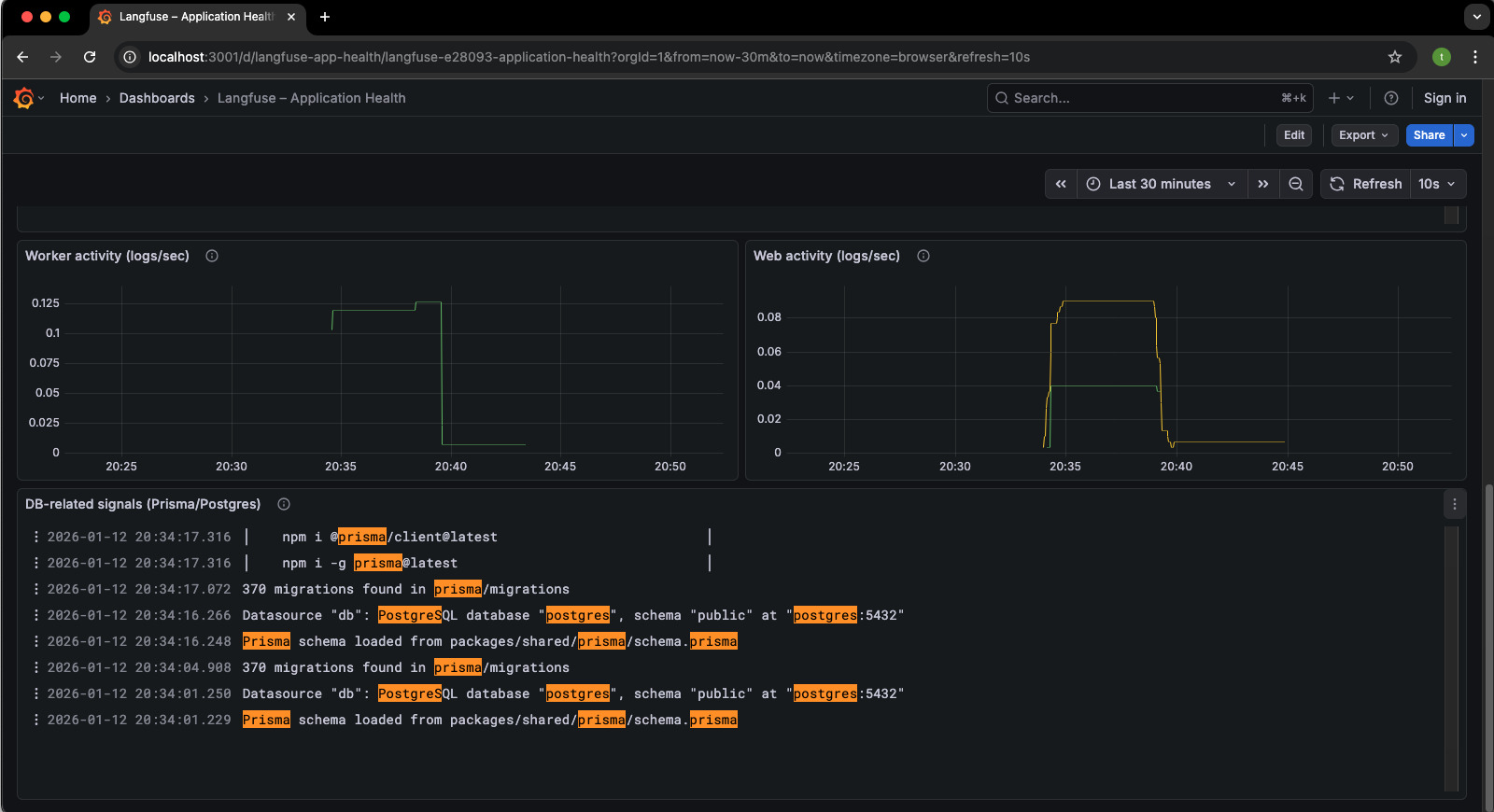
集中追蹤指標、日誌與推論流程,讓 AI 系統由黑盒轉為可觀測,協助團隊理解系統狀態與排查問題。
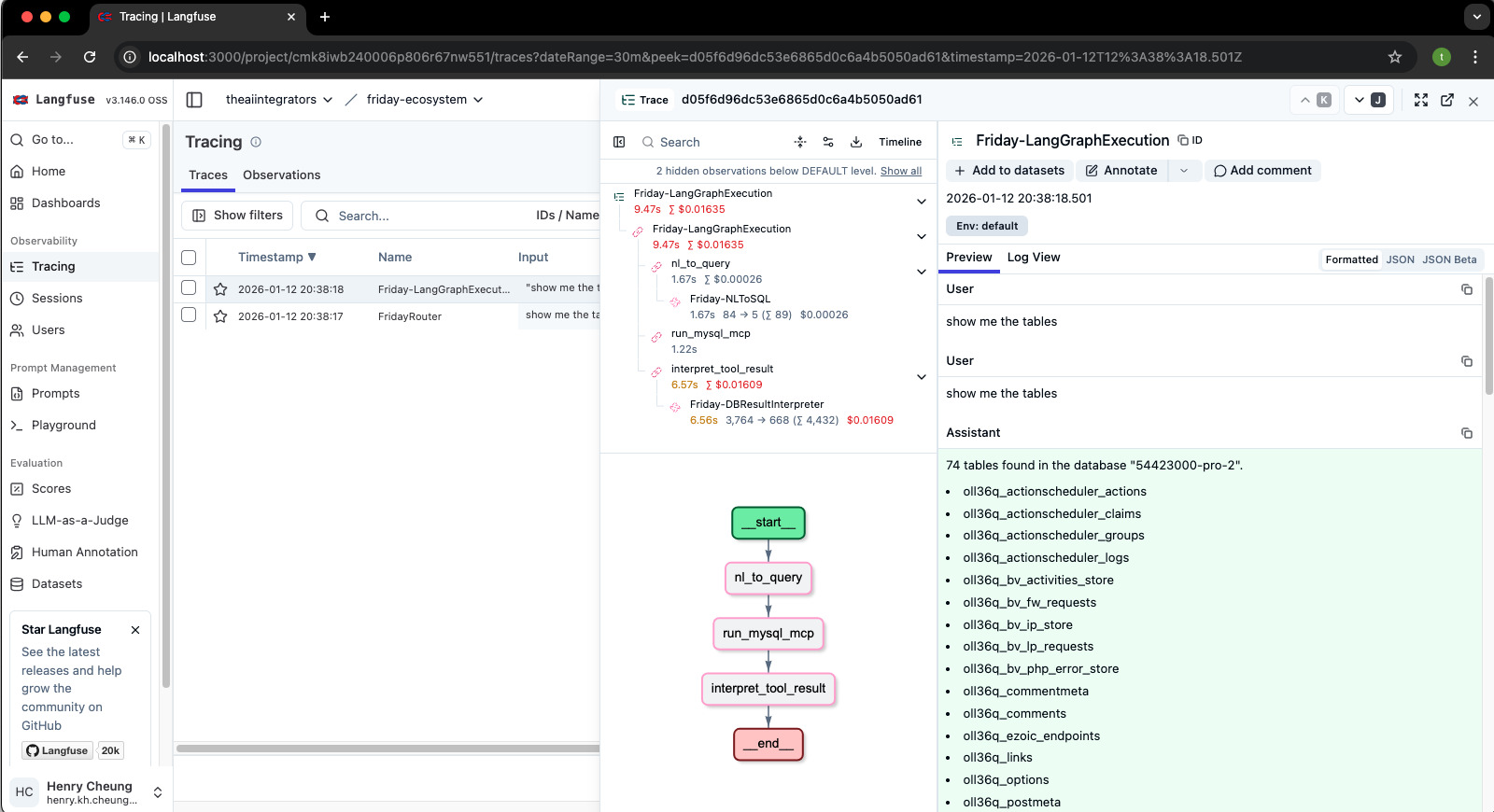
透過指標與流程追蹤數據,分析 AI 系統行為與異常線索,協助團隊進行排錯與優化。
支援 AI 系統的監控、排錯與改善,協助團隊建立可追蹤的運行依據
從觀測資料收集到問題分析,建立可追蹤的 AI 運行與排查流程
AI 系統在運行過程中產生指標(Metrics)、日誌(Logs)與流程追蹤(Traces)。
透過統一機制收集不同來源數據,並按資料政策設定欄位、遮罩與保存方式。
將數據集中管理,支援查詢、關聯分析與歷史回溯。
透過儀表板與分析工具觀察系統狀態,協助發現異常並定位問題。
了解 AI 可觀測性如何協助您監控系統並建立排查依據